This blog has moved from Blogger to Substack. The new link is:
No Set Gauge
In addition, I now have a personal website that has a catalogue of my published writings here.

This blog has moved from Blogger to Substack. The new link is:
We (Flo & Rudolf) spent a month fleshing out the idea of an insurance-for-AI company. We talked to 15 people in the insurance industry, and did 20 customer interviews. We decided not to continue, but we think it’s still a very promising idea and that maybe someone else should do this. This post describes our findings.
To reduce AI risks, it would be good if we understood risks well, and if some organisation existed that could incentivise the use of safer AI practices. An insurance company that sells insurance policies for AI use cases has a financial incentive to understand concrete AI risks & harms well, because this feeds into its pricing. This company would also be incentivised to encourage companies to adopt safer AI practices, and could incentivise this by offering lower premiums in return. Like many cyber-insurance companies, it could also provide more general advice & consulting on AI-related risk reduction.
TL;DR: Currently, professionals (e.g. lawyers) have professional indemnity (PI) insurance. Right now, most AI tools involve the human being in the loop. But eventually, the AI will do the work end-to-end, and then the AI will be the one whose mistakes need to be insured. Currently, this insurance does not exist. We would start with law, but then expand to all other forms of professional indemnity insurance (i.e. insurance against harms caused by a professional’s mistakes or malpractice in their work).
Frontier labs are not good customers for insurance, since their size means they mostly do not need external insurance, and have a big information advantage in understanding the risk.
Instead, we would target companies using LLMs (e.g. large companies that use specific potentially-risky AI workflows internally), or companies building LLM products for a specific industry.
We focused on the latter, since startups are easier to sell to. Specifically, we wanted a case where:
The best example we found was legal LLM tools. Law involves important decisions and large amounts of money, and lawyers can be found liable in legal malpractice lawsuits. LLMs are close to being able to do much legal work end-to-end; in particular, if the work is not checked by a human before being shipped, it is uncertain if existing professional indemnity (PI) insurance applies. People who work in law and law tech are also, naturally, very liability-aware.
Therefore, our plan was:
We thought this could be a multi-billion dollar company, a natural for-profit home for concrete AI risk research, and a reducer of existential risk from AI.
Insurance is about cash-flow management. Sometimes, a low-probability accident happens, that either bankrupts the company or just puts an annoying dent in their accounting. If the expected value of such losses exceeded the company’s ability to pay, (competent) insurers would not be willing to sell the policy. But if it’s less, the company can benefit (by e.g. better weathering sudden shocks) by having insurance, and the insurer can make a profit in expectation.
Another way of describing the core function of insurance is as arbitrage between differently-locally-concave utility functions. Assume the policyholder faces a gamble between a good outcome $$x_2$$ and a bad outcome $$x_1$$. If the policyholder’s utility function is more concave than the insurer’s (for example, if it’s the red line below, while the insurer’s is just linear), then the policyholder cares less than the insurer about the difference between $$x_2$$ and $$x_2$$ minus the insurance premium rate $$r$$. If the policyholder's utility function is $$f$$, the policyholder’s expected utility change given insurance is a rise from $$p f(x_1) + (1-p) f(x_2)$$ (where $$p$$ is the chance of the bad outcome) to just always being $$f(x_2 - r)$$, while the insurer is exposed to upside risk $$(1-p)r$$ (green rectangle) and downside risk $$p(x2-x1-r)$$ (red rectangle). The flatter the policyholder’s utility function $$f$$ is around the $$x_2-r$$ to $$x_2$$ region compared to the region before that, the better this trade can be.

There are other benefits of insurance too:
Insurance depends on scale because of the central limit theorem. As a simplified example, let’s say you’re an insurance company selling flood insurance. Assume you sell flood insurance policies for £100, and there’s a 10% chance that a flood happens and you need to pay out £600 (so the expected risk is £60). In expectation, you make £40 per policy. However, if you sell 10 policies, and suddenly 2 or more of them trigger, you’ve made revenue of £1000 but a loss of £1200 and you’re bankrupt (assume you don’t have cash reserves). There’s a ~26% chance of this happening ($$\sum_{i=0}^{1} [\text{binomial pdf}_{p=0.1, n=10}(i)] \approx 0.26$$). However, if you sold 100 policies, the probability that 2 or more in every set of 10 triggers is only 0.2% ($$\sum_{i=0}^{19} [\text{binomial pdf}_{p=0.1,n=100}(i)] \approx 0.002$$).
Therefore, even if the expected loss is the same between two insurers, assuming the same risk tolerance (a red area), the insurer with more policies is exposed to less variance in expected loss per policy and can set a lower price:
Therefore, the way you achieve good capital efficiency in insurance is to sell many policies across many different types of risk (ideally uncorrelated ones - so not just flood policies, which might all trigger in the case of rising seas, but diverse types of risks).
However, in practice the balance sheets and the actual selling of the insurance products are not very tightly coupled in the insurance industry. You do not have to be a company with huge policy scale, you just have to work with such a company (for example, by becoming an MGA - see below).
The straightforward consequence of the above incentive is that you get monopoly effects in insurance, where one firm achieves the largest balance sheet and then beats everyone else on price (or pushes everyone else into a daredevil game where they’re more likely to blow up than the big one is).
To some extent, this has happened. However, there’s a separate dynamic too. To quote from a blog post by Felix Stocker:
“Most businesses, especially SMEs, buy their insurance from someone they know personally. Because it’s low on the list of priorities, but important to get right, the CEOs or CFOs responsible stick with people they trust - brokers that can answer questions, and be relied upon to bail them out in a tough spot. Personalities, not brands, are key. Because of this, the concept that best explains the structure of the insurance broking market is Dunbar’s Number - the idea that any one person can only hold a limited number of personal relationships. So each broker has up to about a hundred relationships - but no more than that. And since the end-customer relationship is owned by an individual broker, then the challenge becomes aggregating brokers, rather than the customers themselves.”
There are also many ways to bundle and unbundle the different components of insurance. Felix Stocker writes about this here. In brief:
A common starting point for insurance startups is to be MGAs (managing general agents), that handle pricing (and, sometimes, distribution - i.e. selling), but are backed by the balance sheet of a reinsurer. This would’ve been our approach too.
There isn’t an insurance product for every niche risk, because companies often hold general liability insurance that covers basically anything.
However, general liability insurance often comes with exceptions. For example, professional liability (also called errors & omissions) is often left to a separate policy, and terrorism & war -related harms are excluded. Also, complicated new risks like cybersecurity have increasingly tended to get exceptions, and be left to specialised cyber policies.
Based on talking to insurance industry experts, we expect AI-related exceptions to general liability and professional indemnity insurance to be coming. In the meantime, the need for them seems somewhat complex and subtle.
We were loosely inspired by Epoch’s “Direct Approach” for forecasting human-level AI. Specifically, we’d make an argument of the form: if we can show that the outputs of the human and the AI are indistinguishable regarding some property (e.g. mistake rate as assessed by humans), then we should treat them as practically the same regarding related properties (e.g. the probability of causing a malpractice lawsuit).
Specifically, our guess for how to price legal professional indemnity insurance for an AI model/scaffold is:
We would likely only go through this process if we had first done a more checkbox-style check of the AI workflow, including:
We expect there is room for fancier technical solutions to evaluate risk probabilities. However, we caution that the size of a loss is almost entirely not about the AI, but instead about the context of the case: what legal work was being done, what harm the legal error resulted in in the real world, what the judge’s mood was when they were deciding the case (if it went to court), and so on. Even the probability of risk is only partly about the AI; it also depends, for example, on whether the client who received the bad advice decides to sue in the first place. This is why the core of our approach is side-stepping the problem of evaluating legal malpractice harms from scratch, and instead creating an argument for why the AI lawyer does not have more risk (or has some specific factor more risk) than the human lawyer. We effectively want to import the human lawyer claims history used for existing insurance pricing to the AI case.
We did not prioritise thinking of technical approaches to risk evaluation, because we thought much more of the risk was on the market size (thinking the opposite is perhaps the most common failure mode of tech-focused entrepreneurs). However, having a “magical” tech demo would probably be a good way to get your foot in the door. Showing you could’ve accurately predicted past failure rates might be the type of evidence that insurers care a lot about.
It seems reasonable that AI legal PI would therefore be even more tilted towards the substantive errors category than human lawyer PI.
Munich Re has an AI insurance team. Here is their thinking on the state of the AI insurance market.
Orbital Witness, which accelerates legal due diligence in real estate, built their own custom AI insurance product with a real estate insurer called First Title.
We won’t share details about the situations of specific startups that we talked to.
Common reasons for customers not needing insurance for their AI use cases included:
We did find several AI-for-law companies that did want an AI-specific insurance policy. Notably, one of them had seen the need to build their own custom insurance product, working with a specialist insurer in their area (real estate law). Several complained about not finding an off-the-shelf solution, and were willing to pay immediately for an insurance policy that addressed their problem. However, in at least one case this was more of a formality required by a contract.
One theme in many customer conversations was that being financially compensated by insurance is not sufficient to make up for damages, because the real damage is to the reputation of the company in question. This is much harder to insure against. Insurance could help indirectly here (e.g. the fact that you were able to get insurance for your product is some evidence that whatever you’re selling doesn’t blow up too often).
Another theme in many customer conversations that people just aren’t thinking that much about AI risks or harms yet. We think this is a consequence of AIs not being deployed in high-stakes use cases. Many organisations are conservative in their applications of AI and choose to start implementing in low stakes domains, such as internal products and answering simple FAQ questions. Nobody wants to be the first company to have AI publicly fail.
The insurance industry is complicated. The legal industry is also complicated. Neither of us had any background in either. The lack of knowledge was generally fixable (thanks to Claude in particular), but the lack of relevant connections significantly slowed our momentum. Early-stage startup exploration is mostly driven by talking to potential customers. This was helped by the fact that we were mostly talking to AI product companies in these spaces, but still was slow going compared to both of our previous experiences getting customer interviews.
An MGA requires a reinsurer, and this takes a lot of time. This meant that, to get started, we would’ve needed not just customers, but a reinsurer. We did not find a reinsurer who was willing to work with us. If we had kept doing this, we would’ve talked to more reinsurers (perhaps starting with Allianz, who have previously reinsured a drone insurance product). The normal time for a new insuretech startup to get a reinsurer is on the order of 6-24 months.
The insurance industry moves slowly and carefully. This makes sense, since insurance companies that make rash and risky moves probably wouldn’t exist for very long. But it is still a very important cultural difference to, for example, the tech world.
Insurance is overwhelmingly about inductive, not deductive, evidence. Claims histories are the gold standard of evidence in the insurance world. If you don’t have a claims history, you will have a hard time.
Insurance is often reactive, and changes are driven by new types of big losses. The industry perks up and starts paying attention and figuring out how to deal with a given risk when a big loss happens related to that risk. In particular, once a big loss happens, lots of insurance actors will want to know how exposed they are to that type of risk, and either reduce exposure to that risk or make money by insuring against it.
Insurance for AI might only become something reinsurers care a lot about after a big event happens and causes harm.
The insurance industry is financially very large but does not have high valuations. Many insurance companies have extremely large revenues, but insurance companies are often valued at only a 1-3x multiple of their revenues (compared to 20x for tech companies). Allianz makes more revenue than Meta and has almost 10x the assets, but as of writing is valued at 1/10th of Meta.
Also, some vague things about insurance that struck us:
Our rough standard was that if we saw a path to getting a reinsurer onboard in clearly less than 6 months, we would start this company. We had several reasons for wanting to move fast:
We also were bottlenecked by not having insurance industry connections. Insurance, as mentioned above, is a very network-based field. It is true that many insuretech founders do not have insurance backgrounds, but it is still critical that some industry expert is involved very early on in advisory capacity, and probably the first hire needs to be someone with deep insurance connections.
In summary, we think that insurance for AI is a great idea for a team that is less impatient, and has either more insurance connections or great willingness to find networks in insurance.
Former AIG (American Insurance Group) CEO Hank Greenberg once said: “All I want in life is an unfair advantage”. Someone who - unlike us - does have an unfair advantage in insurance may be able to run with this idea, build a great company, and reduce AI risk.
Insurance requires a large balance sheet to pay out claims from. The standard way to solve this is with a reinsurer. However, who else has a lot of capital, and (unlike reinsurers) a specific interest in AI? Foundation model labs (FMLs) and their Big Tech backers.
This could also simultaneously align FML incentives. Incentive-wise, the natural place to park AI risk is at the AI companies themselves. There are two levels of this:
Why might FMLs want to do this? It spreads the risk of things going wrong and incentivises finding errors in other companies’ models early on. It could increase public trust in AI as a whole, which will make adoption easier. In particular, most people don’t know the difference between the top FMLs and so see them as “AI companies.” If one AI company causes a large harm, the public is likely to associate it with AI companies in general. It also seems good, incentive-wise, that the companies driving a technology are the ones who are involved in insuring the risk.
Why might FMLs not want to do this? There are lots of incredibly good reasons.
To try to get around these issues, we explored options for FML backing, including:
We soon reached the point where, with Claude-3.5 serving as our legal team, we were doodling increasingly complicated legal structure diagrams on whiteboards. Some of them were starting to look vaguely pyramid-shaped. That was a good place to leave it.
Why not leave the entire insurance industry to the existing insurance companies, and focus on what we really care about: modelling concrete AI risks?
An example of a company that sells risk models to insurance companies is RMS (now part of Moody’s, after changing ownership a few times). They were started in the late 1980s and specialised in natural catastrophe (“nat cat”) risk modelling. They had a technical moat: they were better at modelling things like synthetic hurricane populations than others.
The main disadvantage of such a route is that selling to insurance companies is very painful: they have slow procurement processes, mostly don’t understand technical details, and generally need to see a long track record of correct predictions before they buy. Venture capitalists are also unlikely to be interested in supporting such a company, since their growth rates are usually not stratospheric. For example, RMS was sold to Moody’s in 2021 for $2 billion, but only after almost 30 years in existence, and after already having been sold to Daily Mail along the way.
Might there be a market apart from insurance companies for a risk modelling product? Maybe, but this is unlikely. For natural catastrophe risks at least, insurance companies dominate risk modelling demand by sheer volume - they want updates all the time, whereas governments might want an update for planning purposes once every decade. Given how fast AI changes, though, there may be more actors who have a high rate of demand for risk models and updates on them.
We haven’t thought about this much, but an org with an AI evaluation/auditing background might be well-placed to move into the insurance (or risk-modelling) space.
We’d like to thank Felix Stocker for lots of great advice on how things work in insuretech, Ed Leon Klinger for sharing his insurtech journey, Robert Muir-Woods for a very helpful chat about RMS, Otto Beyer for a valuable initial conversation about the insurance space, Jawad Koradia for helping us get initial momentum and introductions, Will Urquhart for talking with us about underwriting niche risks, the team at Entrepreneur First (in particular Kitty Mayo, Dominik Diak, and Jack Wiseman) for hosting much of our exploration and offering advice & introductions, and various people scattered across AI startups and the insurance industry for taking time to meet with us.

Everyone who starts thinking about AI starts thinking big. Alan Turing predicted that machine intelligence would make humanity appear feeble in comparison. I. J. Good said that AI is the last invention that humanity ever needs to invent.
The AI safety movement started from Eliezer Yudkowsky and others on the SL4 mailing list discussing (and aiming for) an intelligence explosion and colonizing the universe. However, as the promise of AI has drawn nearer, visions for AI upsides have paradoxically shrunk. Within the field of AI safety, this is due to a combination of the “doomers” believing in very high existential risk and therefore focusing on trying to avoid imminent human extinction rather than achieving the upside, people working on policy not talking about sci-fi upsides to look less weird, and recent progress in AI driving the focus towards concrete machine learning research rather than aspirational visions of the future.
Both DeepMind and OpenAI were explicitly founded as moonshot AGI projects (“solve intelligence, and then use that to solve everything else” in the words of Demis Hassabis). Now DeepMind - sorry, Google DeepMind - has been eaten by the corporate machinery of Alphabet, and OpenAI is increasingly captured by profit and product considerations.
The torch of AI techno-optimism has moved on the e/acc movement. Their core message is correct: growth, innovation, and energy are very important, and almost no one puts enough emphasis on them. However, their claims to take radical futures seriously are belied by the fact that their visions of the future seem to stop at GenAI unicorns. They also seem to take the general usefulness of innovation not as just a robust trend, but as a law of nature, and so are remarkably incurious about the possibility of important exceptions. Their deeper ideology is in parts incoherent and inhuman. Instead of centering human well-being, they worship the “thermodynamic will of the universe”. “You cannot stop the acceleration”, argues their figurehead, so “[y]ou might as well embrace it” - hardly an inspiring humanist rallying cry.
In this piece, we want to paint a picture of the possible benefits of AI, without ignoring the risks or shying away from radical visions. Why not dream about the future you hope for? It’s important to consider the future you want rather than just the future you don’t. Otherwise, you might create your own unfortunate destiny. In the Greek myth about Oedipus, he was prophesied to kill his father, so his father ordered him to be killed, but he wasn’t and ended up being adopted. Years later he crossed his father on the road in his travels and killed him, as he had no idea who his father was. Oedipus’ father focusing on the bad path might have made the prophecy happen. If Oedipus' father hadn’t ordered him to be killed, he would have known who his father was and likely wouldn’t have killed him.
When thinking about AI, if we only focus on the catastrophic future, we may cause it to become true by causing an increase in attention on this topic. Sam Altman, who is leading the way in AI capabilities, claimed to have gotten interested from arch-doomer Eliezer Yudkowsky. We may also neglect progress towards positive AI developments; some people think that even direct AI alignment research should not be published because it might speed up the creation of unaligned AI.

With modern AI, we might even get a very direct “self-fulfilling prophecy” effect: current AIs increasingly know that they are AIs, and make predictions about how to act based on their training data which includes everything we write about AI.
Since we think a large focus of AI is on what could go wrong, let’s think through what could go well starting from what’s most tangible and close to the current usage of AI to what the more distant future could hold.
Already, AI advances mean that Claude has beocme very useful, and programmers are faster and better. But below we’ll cast a look towards the bigger picture and where this could take us.
First, there’s a lot of mundane mental work that humans currently have to do. Dealing with admin work, filing taxes, coordinating parcel returns -- these are not the things you will fondly be reminiscing about as you lie on your deathbed. Software has reduced the pain of dealing with such things, but not perfectly. In the future, you should be able to deal with all administrative work by specifying what you want to get done to an AI, and being consulted on decision points or any ambiguities in your preferences. Many CEOs or executives have personal assistants; AIs will mean that everyone will have access to this.
What about mundane physical work, like washing the dishes and cleaning the toilets? Currently, robotics is bad. But there is no known fundamental obstacle to having good robotics. It seems mainly downstream of a lot of engineering and a lot of data collection. AI can help with both of those. The household robots that we’ve been waiting for could finally become a reality.
Of course, it is unclear whether AIs will first have a comparative advantage against humans in mundane or meaningful work. We’re already seeing that AI models are making massive strides in making art, way before they’re managing our inboxes for us. It may be that there is a transitional period where robotics is lagging but AIs are smarter-than-human, where the main economic value of humans is their hands rather than their brains.
With AI agents being able to negotiate with other AI agents, the cost of coordination is likely to dramatically drop (see here for related discussion). Examples of coordination are agreements between multiple parties, or searching through a large pool of people to match buyers or sellers, or employees and employers. Searching through large sets of people, doing complex negotiations, and the monitoring and enforcement of agreements all take lots of human time. AI could reduce the cost and time taken by such work. In addition to efficiency gains, new opportunities for coordination will open up that would have previously been too expensive.
To give an example of this on the small scale of two individuals, say you are trying to search for a new job. Normally you can’t review every single job posting ever, and employers can’t review every person in the world to see if they want to reach out. However, an AI could filter that for the individual and another AI for the business, and the two AIs could have detailed negotiations with each other to find the best possible match.
A lot of the current economy is a coordination platform; that’s the main product of each of Google, Uber, Amazon, and Facebook. Reducing the cost of searching for matches and trades should unlock at least as much mundane benefits and economic value as the tech platforms have.
Increased coordination may also reduce the need to group people into roles, hierarchies, and stereotypes. Right now, we need to put people into rigid structures (e.g. large organisations with departments like “HR” or “R&D”, or specific roles like “doctor” or “developer”) when coordinating a large group of people. In addition to upholding standards and enabling specialisation of labour, another reason for this is that people need to be legible to unintelligent processes, like binning of applicants by profession, or the CEO using an org chart to find out who to ask about a problem, or someone trying to buy some type of service. Humans can reach a much higher level of nuance when dealing with their friends and immediate colleagues. The cheap intelligence we get from AI might let us deal with the same level of nuance with a larger group of people than humans can themselves track. This means people may be able to be more unique and differentiated, while still being able to interface with society.
On a larger scale, increased coordination will also impact geopolitics. Say there are two countries fighting over land or resources. Both countries could have AI agents to negotiate with the other AI agents to search the space of possible deals and find an optimal compromise for both. They could also simulate a vast number of war scenarios to figure out what would happen; much conflict is about two sides disagreeing about who would win and resolving the uncertainty through a real-world test. This relies on three key abilities: the ability to negotiate cheaply, the ability to simulate outcomes, and the ability to stick to and enforce contracts. AI is likely to help with all three. This could reduce the incentives for traditional war, in that no human lives are needed to be lost because the outcome is already known and we can negotiate straight from that. We also know exactly what we are and are not willing to trade off which means it’s easier to optimise for the best compromise for everyone.
AI lets us spread the benefits of being smart more widely.
The benefits of intelligence are large. For example, this study estimates that a 1 standard deviation increase in intelligence increases your odds of self-assessed happiness by 11%. Now, part of this gain comes from intelligence being a positional good: you benefit from having more intelligence at your disposal than others, for example in competing for a fixed set of places. However, intelligence also has absolute benefits, since it lets you make better choices. And AI means you can convert energy into intelligence. Much as physical machines let the weak gain some of the benefits of (even superhuman) strength, AI might allow all humans to enjoy some of the benefits of being smart.
Concretely, this could have two forms. The first is that you could have AI advisors increase your ability to make plans or decisions, in the same way that - hypothetically - even a near-senile president might still make decent decisions with the help of their smart advisors. With AI, everyone could have access to comparable expert advisors. The effect may be even more dramatic than human advisors: the AI might be superhumanly smart, the AI might be more verifiably smart (a big problem in selecting smart advisors is that it can be hard to tell who is actually smart, especially if you are not), and if AIs are aligned successfully there may be less to worry about in trusting it than in trusting potentially-scheming human advisors.
The second is AI tutoring. Human 1-1 tutoring boosts educational outcomes by 2 standard deviations (2 standard deviations above average is often considered the cutoff for “giftedness”). If AI tutoring is as good, that’s a big deal.
AI is special because it automates intelligence, and intelligence is what you need to build technology, including AI, creating a feedback loop. Some other previous technologies have boosted other technologies; for example, the printing press massively helped the accumulation of knowledge that led to the invention of many other technologies. But we have not before had a technology that could itself directly advance other technology. Such AI has been called PASTA (Process for Automating Scientific and Technological Advancement).
Positive feedback loops - whether self-improving AIs, nuclear reactions, epidemics, or human cultural evolution - are very powerful, so you should be wary of risks from them. Similarly, it is currently at best extremely unclear whether AIs that improve themselves could be controlled with current technology. We should be very cautious in using AI systems to improve themselves.
In the long run, however, most of the value of AI will likely come from their effects on technological progress, much like the next industrial revolution. We can imagine AIs slashing the cost and increasing the speed of science in every field, curing diseases and making entire new veins of technology available, in the same way that steam engines made entirely new veins of coal accessible.
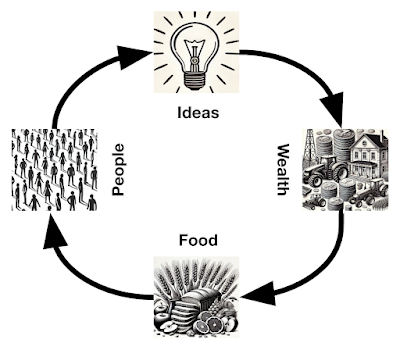
In particular, AIs help de-risk one of the largest current risks to future human progress. One model of the feedback loop behind humanity’s progress in the past few centuries is that people led to ideas led to wealth led to food led to more people.
However, greater wealth no longer translates into more people. The world population, which was exponentially growing for much of the 19th and 20th centuries, is likely to be in decline by the end of the 21st century. This is likely to have negative consequences for the rate of innovation, and as discussed in the next section, a decline in productivity would likely have a negative impact on human wellbeing. However, if AIs start driving innovation, then we have a new feedback loop: wealth leads to energy leads to more AIs leads to ideas leads to wealth.
As long as this feedback loop does not decouple from the human economy and instead continues benefitting humans, this could help progress continue long into the future.
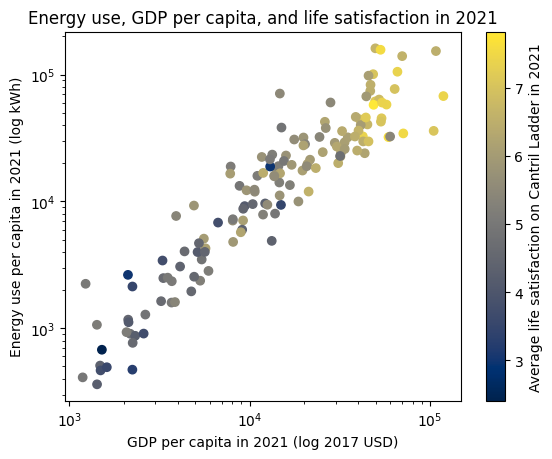
If you want humans to be well-off, one of the easiest things to do is give them more wealth and more energy. GDP per capita (on a log scale) has a 0.79 correlation with life satisfaction, and per-capita energy use (again on a log scale) has a 0.74 correlation with life satisfaction. Increased wealth and energy correlate with life satisfaction, and we should expect these trends to continue.
Above: GDP per capita (x-axis), energy use (y-axis), and life satisfaction (colour scale) for 142 countries. There are no poor countries with high energy use, and no high energy use countries that are poor. There are no countries with high average life satisfaction that are not high in both energy use and average GDP per capita. The axes are logarithmic, but since economic growth is exponential, countries should be able to make progress at a constant rate along the axis. Data source: Our World In Data (here, here, and here).
(It is true that energy use and economic growth have been increasingly decoupling in rich countries, due to services being more of the economy, and efficiency gains in energy use. However, the latter is effectively increasing the amount of useful energy that can be used - e.g. say the amount of energy needed to cook one meal is now enough to cook two meals, which is effectively the same as gaining more energy. However, efficiency effects are fundamentally limited because there is a physical limit, and also if demand is elastic then efficiency gains lead to increased energy use, meaning it doesn’t help the environment either. Ultimately, if you want to do more things in the physical world, you need more energy).
A wealthy, energy-rich society has many material benefits: plentiful food, advanced medicine, high redistributive spending becomes feasible, and great choice and personal freedom through specialisation of labour and high spending power. A wealthy and energy-rich society also has some important subtler benefits. Poverty and resource constraints sharpen conflict. Economic growth is intimately linked to tolerance and liberalism, by weakening the cultural status and clout of zero-sum strategies like conflict and politicking.
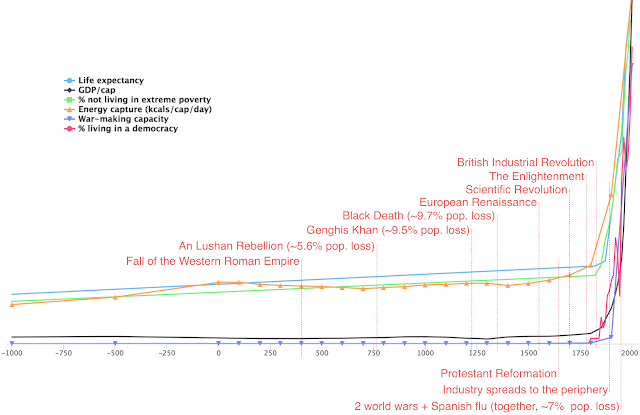
One clear historic example of how increases in energy correlated with improved quality of life was in the industrial revolution, arguably the best and most important thing that ever happened. Before it, trends in human wellbeing seemed either stagnant, fluctuating, or very slow, and after it, all the variables for which we can find good long-term series that are related to human well-being shoot upwards.
Above: variables correlated with human well-being over time. Source: Luke Muehlhauser
Therefore, it’s worth keeping in mind that boosting energy and wealth is good, actually. And the most powerful way to do that is through inventing new technologies that let us use energy to serve our needs.
The heart of the industrial revolution was replacing part of human manual labour with something cheaper and more powerful. AI that replaces large parts of human mental labour with something cheaper and more powerful should be expected to be similarly transformative. Whether it is a good or bad transformation seems more uncertain. We are lucky that industrialisation happened to make national power very tightly tied to having a large, educated, and prosperous middle class; it is unclear what is the winning strategy in an AI economy. We are also lucky that the powerful totalitarian states enabled by industrial technology have not triumphed so far, and they might get further boosts from AI. Automating mental labour also involves the automation of decision-making, and handing over decision-making to the machines is handing over power to machines, which is more risky than handing the manual labour to them. But if we can safely control our AI systems and engineer good incentives for the resulting society, we could get another leap in human welfare.
Now say we’ve had a leap in innovation and energy through Transformative AI (TAI) and we’ve also reached a post scarcity world. What happens now? Humans have had all their basic needs met, most jobs are automated, but what do people spend their time actually doing?
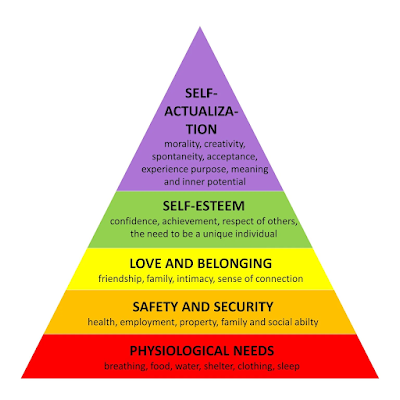
Maslow’s hierachy of needs is a framework of understanding human needs and drivers for human behaviour. Maslow suggested that in most scenarios people need to mostly satisfy one level before being able to focus on higher-level needs.
The top level of the hierachy is self-actualisation. The peak of human experience is something that few can currently reach - but maybe everyone could get there.
There is a possible path the world takes in which all humans can reach self-actualisation. With increases in technology & wealth, such as with TAI and a Universal Basic Income (UBI), we would be able to provide the basic needs of food, water, shelter, and clothing for all humans, enabling people to easily meet their basic needs. Humans can now spend more time on the things they want, for example moving up through Maslow’s hierarchy to focusing on increasing love and belonging, self-esteem and self-actualization.
Say you are in a post scarcity world, what would you do if you didn’t have to work?
Would you be spending time with loved ones, engaging in social activities that provide a sense of connection and belonging, self-esteem? Would it be honing your craft and becoming an expert in a particular field? Or would you spend the whole time scrolling on your phone?
Say hypothetically a wealthy billionaire gave you a grant to work on anything you wanted, would you be happy with having the complete freedom to spend your time as you wished?
Often people assume that others will be unhappy with this world, but would you? There is a cognitive bias where people tend to judge themselves as happier than their peers, which could nudge you to think people would be less happy in this world, even if you would enjoy this.
In this post-scarcity world, humans could spend more time on creative pursuits such as art, music, and any other hobbies – not with the goal of making money, but to reach self-actualisation.
With AI being better than humans in every dimension, AI can produce the best art in the world, but there is intrinsic value in honing your craft, improving at art or expressing your feelings through it, in and of itself. The vast majority of art is not created to be the best art in the world but for the journey itself. A child that paints a finger painting and the parent who puts it on the wall does not think “my child’s art is better than Van Gogh’s”. Instead, they feel a sense of excitement about the progress their child has made and the creative expression the child has produced.
Another example is the Olympic games. Nobody needs to win the olympic games to survive, but it lets people express pride in their country, hone their craft, attain status, and so on. But the actual task is just a game, a social construct. More and more tasks will look like social constructs and games we create to challenge each other.
Since this is quite theoretical, let's consider examples where we’ve had “post-scarcity” microcosms to explore.
The French leisure class, or bourgeoisie, were a class of wealthy elite that emerged in 16th century France. Many had enough money to pursue endeavours like refining their taste in arts and culture. Salon culture was a cornerstone of bourgeoisie social life. Gatherings featuring discussions on literature, art, politics and philosophy.
The upper class in the Victorian era enjoyed a variety of leisure activities that reflected their wealth, status and values. They attended social events and balls, fox hunting and other sports, theater and opera, art and literature, travel, tea parties and social visits, gardening and horticulture, charitable work and philanthropy. Several undertook serious pursuits in science or art.
Burning Man is an annual festival where people take all the basic things you need with you for a week of living in the desert:food, water, shelter. People have a week to create a new community or city that is a temporary microcosm of a post-scarcity world. They pursue artistic endeavours and creative expression, music, dance and connecting with others. People often talk about Burning Man events being some of the best experiences of their lives.
In San Francisco, there is a crossover with hippie culture and tech, and many people with excess wealth and resources, resulting in many looking for more in life. They try to reach self actualisation, by pursuing many arts and creative pursuits. Hippie movements often encourage communal living, and a sense of connection with those around you. Many may raise eyebrows at the lifestyles of some such people, but it’s hard to claim that it’s a fundamentally bad existence.
It is true that not all cultural tendencies in a post-scarcity world would be positive. In particular, humans have a remarkable ability to have extremely tough and all-consuming social status games, seemingly especially in environments where other needs are met. See for example this book review about the cut-throat social scene of upper-class Manhattan women or this one about the bland sameness and wastefulness of nightlife, or this book review that ends up concluding that the trajectory of human social evolution is one long arc from prehistoric gossip traps to internet gossip traps, with liberal institutions just a passing phase.
But the liberal humanist attitude here is to let humans be humans. Yes, they will have petty dramas and competitions, but if that is what they want, who is to tell them no? And they will also have joy and love.
Would a post-scarcity world have meaning? Adversity is one of the greatest sources of meaning. Consider D-Day, when hundreds of thousands of soldiers got together to charge up a beach under machine-gun fire to liberate a continent from Nazi rule. Or consider a poor parent of four working three jobs to make ends meet. There are few greater sources of meaning. But adversity can be meaningful while involving less suffering and loss. A good future will be shallower, in a sense, but that is a good thing.
Finally, it is unclear if we would get a happy world, even if we had the technology for post-scarcity, because of politics and conflict. We will discuss this later.
AI might also help with radical but necessary improvements to the human condition.
People die. It is a moral tragedy when people are forced to die against their will, as happens to over 50 million people per year. Medicine is making progress against many causes of death and disability; in the limit it can cure all of them. We should reach that limit as fast as possible, and AI can likely help accelerate the research and deployment of solutions.
One of the greatest inequalities in the world is inequality in intelligence. Some people struggle to perform in simple jobs, while others (well, at least one) are John von Neumann. In the short term, AI might help by making cognitively demanding tasks more accessible to people through AI tutors and AI copilots. In the longer term, AI might help us enhance human intelligence, through brain-AI integration or new medical technology.
Though there are many potential upsides for AI and AGI as argued in this post, that doesn’t mean there aren’t risks.
The plausible risks of AI go all the way to human extinction, meaning this shouldn’t be taken lightly. Since this piece is focused on the upside risk, not the downside risk, we will not argue this point in depth, but it is worth revisiting briefly.
It is intuitive that AI is risky.
First, creating something smarter, faster, and more capable than humans is obviously risky, since you need to very precisely either control it (i.e. stop it from doing things you don’t like) or align it (i.e. make it always try to do what you would want it to do). Both the control and alignment problem for AIs still have unsolved technical challenges. And that’s assuming that AI is in the right hands.
Second, even if the AIs remain in our control, they are likely to be as transformative as the industrial revolution. Eighteenth-century European monarchs would’ve found it hard to imagine how the steam engine could challenge their power, but the social changes that were in part a result of them eventually wrested all their powers away. In the modern world, a lot of power depends on large educated workforces of humans, whereas sufficiently strong AGI might decorrelate power and humans, decreasing the incentive to have people be educated and prosperous - or to have people around at all.
Apart from object-level arguments, consider too the seriousness with which the AI doomsday is discussed. Many top researchers and all top AI lab CEOs have signed a statement saying “Mitigating the risk of extinction from AI should be a global priority alongside other societal-scale risks such as pandemics and nuclear war”. Nuclear war and pandemics are the only other cases where similarly serious predictions have been made by a similarly serious set of people (though arguably climate change is close: the science on the effects is more established and certain, but while catastrophe is more likely, literal human extinction from it is much less likely).
Consider the internet, a widely-successful technology with a lot of benefits. There are credible claims that the internet is responsible for harms ranging from massively increased depression rates among teenagers to political polarisation to widespread productivity loss through addiction and distraction.
In the same way, the success of AI might lead to bad side effects, even if all the existential risks are avoided.
For example, AI could replace human connection. Human friends and partners might increasingly be replaced with AIs. However bad it was in other ways, at least on pre-AI social media you at least interacted with humans (or simple algorithms), but with AIs it’s possible to have what looks like deep emotional relationships. Just look at the Replika subreddit from a year ago when they changed the algorithm to only allow “PG-rated interactions”. Many users were upset. The film “Her” doesn’t seem far off, as Sam Altman acknowledges. Such relationships give the human much more safety and control than in human relationships, which might both be very attractive to humans, while also excessively coddling them. Given that much human happiness and meaning comes from human relationships and bonding, widespread AI substitution of them could mean the destruction of a large part of all human wellbeing and meaning in the world. On a more prosaic level, society might atomise into individuals hoarding compute credits to spend on running their AI companions without connecting with other humans, with severe effects on society’s functioning, or humans might stop having children and human populations might crash. Humanity has flourished through collaboration and socialisation. If we use AIs to replace this in an overly thoughtless way, the fabric of society could crumble.
Apart from being superhuman at forming relationships with humans, AIs might be superhuman at persuasion. We can imagine AIs producing the vast majority of content that people consume. We can imagine a totalitarian world where the governments with the greatest compute resources can dominate the conversation forever. Instead of humans having ideas and sometimes persuading other humans to adopt them, driving social progress, any human-generated ideas might be swamped by a greater quantity of superhumanly persuasive counter-arguments that support the status quo. We can also imagine a dystopian decentralised world. Already, many online memes (in Dawkins’s original sense of the word) are maladaptive, spreading not by having good effects on their hosts but by being incredibly good at spreading from person to person. AI might make us much better at searching the space of ideas for the most viral ones. Ideas that aren’t maximally viral might be outcompeted. Eventually, our institutions could become mere puppets that serve as viral hosts for the most transmissive memes, as part of an endless tug-of-war where AI-generated memes compete to compel humans to spread them.
Seems bad.
Many debates turn into mood affiliation debates. Are guns bad? Is more government good? But remember: politics is the mindkiller. Navigating a complicated world requires more than the ability to stick the label “good” or “bad” on entire domains. If you were seated in the control room of a nuclear power station, you wouldn’t ask yourself: uranium, good or bad? Instead, you want to steer towards the small set of states where the reaction is perched between dying out and exploding, while generating useful clean power.
We’ve also seen again and again that technology and social change have strong effects on each other, and these are often hard to predict. We’ve discussed how industrial technology may have led to democracy. There is serious academic debate about whether the stirrup caused feudalism, or whether the Black Death was a driver of European liberalism, or whether social media was a significant cause of the Arab Spring. The birth control pill was a major influence of the sexual revolution, and the printing press helped the Protestant Reformation. Often, the consequences of a new technology are some obvious direct benefits, some obvious direct harms, and the shifting of some vast social equilibrium that ends up forever reshaping the world in some way no one saw coming. So far we’ve clearly ended up ahead on net, and maybe that will continue.
Humanity has spent over a hundred thousand years riding a feedback loop of accumulating cultural evolution. Over the past few hundred, the industrial revolution boosted the technological progress feedback loop. Human wellbeing has skyrocketed, though along the way we’ve had - and are continuing to have - close calls with nuclear war, totalitarianism, and environmental issues. We’ve had a healthy dose of luck, including in generalities like the incentive structures of industrial economics and specifics like the heroism of Stanislav Petrov. But we’ve also had an enormous amount of human effort and ingenuity spent on trying to chart a good path for civilization, from solar panel subsidies to the Allies winning World War 2.
For most of this time, the direction of the arrow of progress has been obvious. The miseries of poverty and the horrors of close-up totalitarianism are very powerful driving forces after all. And while both continue ravaging the world, developed countries have in many ways gotten complacent. There are fewer obvious areas of improvement for those lucky enough to enjoy a life of affluence in the developed world. But the future could be much better still.
We think it’s important to have a target of what to aim for. We need to dream about the future we want. A strong culture needs a story of what it is driving towards, and humanity needs a compelling vision of how our future turns out well so we can work together to create the future we all want. AI seems like the biggest upcoming opportunity and risk. We hope we can avoid the risks, and realise the positive vision presented here, together with a hundred other things we can’t yet imagine.
See LessWrong for additional comments & discussion.
~4k words (20 minutes)
Doing research means answering questions no one yet knows the answer to. Lots of impactful projects are downstream of being good at this. A good first step is to have a model for what the hard parts of research skill are.
There are two opposing failure modes you can fall into when thinking about research skill.
The first is the deferential one. Research skill is this amorphous complicated things, so the only way to be sure you have it is to spend years developing it within some ossified ancient bureaucracy and then have someone in a funny hat hand you a piece of paper (bonus points for Latin being involved).
The second is the hubristic one. You want to do, say, AI alignment research. This involves thinking hard, maybe writing some code, maybe doing some maths, and then writing up your results. You’re good at thinking - after all, you read the Sequences, like, 1.5 times. You can code. You did a STEM undergrad. And writing? Pffft, you’ve been doing that since kindergarten!
I think there’s a lot to be said for hubris. Skills can often be learned well by colliding hard with reality in unstructured ways. Good coders are famously often self-taught. The venture capitalists who thought that management experience and a solid business background are needed to build a billion-dollar company are now mostly extinct.
It’s less clear that research works like this, though. I’ve often heard it said that it’s rare for a researcher to do great work without having been mentored by someone who was themselves a great researcher. Exceptions exist and I’m sceptical that any good statistics exist on this point. However, this is the sort of hearsay an aspiring researcher should pay attention to. It also seems like the feedback signal in research is worse than in programming or startups, which makes it harder to learn.
To answer this question, and steer between deferential confusion and hubristic over-simplicity, I interviewed people who had done good research to try to understand their models of research skill. I also read a lot of blog posts. Specifically, I wanted to understand what about research a bright, agentic, technical person trying to learn at high speed would likely fail at and either not realise or not be able to fix quickly.
I did structured interviews with Neel Nanda (Google DeepMind; grokking), Lauro Langosco (Krueger Lab; goal misgeneralisation), and one other. I also learned a lot from unstructured conversations with Ferenc Huszar, Dmitrii Krasheninnikov, Sören Mindermann, Owain Evans, and several others. I then ~procrastinated on this project for 6 months~ touched grass and formed inside views by doing the MATS research program under the mentorship of Owain Evans. I owe a lot to the people I spoke to and their willingness to give their time and takes, but my interpretation and model should not taken as one they would necessarily endorse.
My own first-hand research experience consists mainly of a research-oriented CS (i.e. ML) master’s degree, followed by working as a full-time researcher for 6 months and counting. There are many who have better inside views than I do on this topic.
In summary:
Empirically, it seems that a lot of the value of senior researchers is a better sense of which questions are important to tackle, and better judgement for what angles of attack will work. For example, good PhD students often say that even if they’re generally as technically competent as their adviser and read a lot of papers, their adviser has much better quick judgements about whether something is a promising direction.
When I was working on my master’s thesis, I had several moments where I was working through some maths and get stuck. I’d go to one of my supervisors, a PhD student, and they’d have some ideas on angles of attack that I hadn’t thought of. We’d work on it for an hour and make more progress than I had in several hours on my own. Then I’d go to another one of my supervisors, a professor, and in fifteen minutes they’d have tried something that worked. Part of this is experience making you faster at crunching through derivations, and knowing things like helpful identities or methods. But the biggest difference seemed to be a good gut feeling for what the most promising angle or next step is.
I think the fundamental driver of this effect is dealing with large spaces: there are many possible ways reality could be (John Wentworth talks about this here), and many possible things you could try, and even being slightly better at honing in on the right things helps a lot. Let’s say you’re trying to prove a theorem that takes 4 steps to prove. If you have a 80% chance of picking the right move at each step, you’ll have a 41% chance of success per attempt. If that chance is 60%, you’ll have a 13% chance – over 3 times less. If you’re trying to find the right hypothesis within some hypothesis space, and you’ve already managed to cut down the entropy of your probability distribution over hypotheses to 10 bits, you’ll be able to narrow down to the correct hypothesis faster and with fewer bits than someone whose entropy is 15 bits (and who’s search space is therefore effectively 25 = 32 times as large). Of course, you’re rarely chasing down just a single hypothesis in a defined hypothesis class. But if you’re constantly 5 extra bits of evidence ahead compared to someone in what you’ve incorporated into your beliefs, you’ll make weirdly accurate guesses from their perspective.
Why does research taste seem to correlate so strongly with experience? I think it’s because the bottleneck is seeing and integrating evidence into your (both explicit and intuitive) world models. No one is close to having integrated all empirical evidence that exists, and new evidence keeps accumulating, so returns from reading and seeing more keep going. (In addition to literal experiments, I count things like “doing a thousand maths problems in this area of maths” as “empirical” evidence for your intuitions about which approaches work; I assume this gets distilled into half-conscious intuitions that your brain can then use when faced with similar problems in the future)
This suggests that the way to speed-run getting research taste is to see lots of evidence about research ideas failing or succeeding. To do this, you could:
Chris Olah has a list of suggestions for research taste exercises (number 1 is essentially the last point on my list above).
Research taste takes the most time to develop, and seems to explain the largest part of the performance gap between junior and senior researchers. It is therefore the single most important thing to focus on developing.
(If taste is so important, why does research output not increase monotonically with age in STEM fields? The scary biological explanation is that fluid intelligence (or energy or …) starts dropping at some age, and this decreases your ability to execute on maths/code, even assuming your research taste is constant or improving. Alternatively, hours used on deep technical work might tend to decline with advanced career stages.)
I heard several people saying that junior researchers will sometimes jump to conclusions, or interpret their evidence as saying more than it actually does. My instinctive reaction to this is: “wait, but surely if you just creatively brainstorm the ways the evidence might be misleading, and take these into account in making your conclusions (or are industrious about running additional experiments to check them), you can just avoid this failure mode?” The average answer I got was that yes, this seems true, and indeed many people either only need one peer review cycle to internalise this mindset, or pretty much get it from the start. Therefore, I’m almost tempted to chuck this category off this list, and onto the list of less crucial things where “be generally competent and strategic” will sort you out in a reasonable amount of time. However, two things hold me back.
First, confirmation bias is a strong thing, and it seems helpful to wave a big red sign saying “WARNING: you may be about to experience confirmation bias”.
Second, I think this is one of the cases where the level of paranoia required is sometimes more than you expect, even after you expect it will be high. John Wentworth puts this best in You Are Not Measuring What You Think You Are Measuring, which you should go read right now. There are more confounders and weird effects than are dreamt of in your philosophies.
A few people mentioned going through the peer review process as being a particularly helpful thing for developing paranoia.
I started out sceptical about the difficulty of research-specific communication, above and beyond general good writing. However, I was eventually persuaded that yes, research-specific communication skills exist and are important.
First, if research has impact, it is through communication. Rob Miles once said (at a talk) something along the lines of: “if you’re trying to ensure positive AGI outcomes through technical work, and you think that you are not going to be one of the people who literally writes the code for it or is in the room when it’s turned on, your path to impact lies through telling other people about your technical ideas.” (This generalises: if you want to drive good policy through your research and you’re not literally writing it …, etc.) So you should expect good communication to be a force multiplier applied on top of everything else, and therefore very important.
Secondly, research is often not communicated well. On the smaller scale, Steven Pinker moans endlessly – and with good reason – about academic prose (my particular pet peeve is the endemic utilisation of the word “utilise” in ML papers.). On the larger scale, entire research agendas can get ignored because the key ideas aren’t communicated in a sufficiently clear and legible way.
I don’t know what’s the best way to speed-run getting good at research communication. Maybe read Pinker to make sure you’re not making predictable mistakes in general writing. I’ve heard that experienced researchers are often good at writing papers, so maybe seek feedback from any you know (but don’t internalise the things they say that are about goodharting for paper acceptance). With papers, understand how papers are read. Some sources of research-specific communication difficulty I can see are (a) the unusually high need for precision (especially in papers), and (b) communicating the intuitive, high-context, and often unverbalised-by-default world models that guide your research taste (especially when talking about research agendas).
(I have already linked to some of these above.)